
导语:AI编程工具效率飙升的当下上海正规手机股票配资论坛,初级开发者岗位面临重构风险
一、AI编程工具进化简史:从助手到生产者
技术案例:GitHub Copilot对重复代码的自动补全
1.技术场景:CRUD接口的重复性本质
在Spring Boot开发中,CRUD(增删改查)接口是基础但高频的需求。例如用户管理系统需实现:
GET /users(查询用户列表)
POST /users(创建用户)
PUT /users/{id}(更新用户)
DELETE /users/{id}(删除用户)

传统开发中,程序员需手动编写实体类、Controller、Service、Repository层代码,耗时且易出错。
2.Copilot的自动补全机制
当开发者输入自然语言指令(如“生成基于Spring Boot和MySQL的User实体CRUD接口”)时,Copilot通过以下步骤生成代码:
A.解析上下文识别当前项目结构、已有注解(如@Entity)及依赖库(如Spring Data JPA)。
B.生成关键组件
实体类:自动创建带JPA注解的User类(含id, name, email等字段)。
Repository接口:生成继承JpaRepository的接口,内置save,findAll等方法。
Service层:编写业务逻辑(如参数校验、事务管理)。
Controller层:生成RESTful端点,映射HTTP方法到Service方法。
C.生成结果示例
Java
// Controller片段(自动生成)
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserService userService;
@GetMapping
public List getAllUsers {
return userService.findAll;
}
// 其他CRUD方法...
}
3.效率提升的核心逻辑
A.效率提升的核心逻辑
效率提升的本质在于将重复性劳动转化为AI驱动的自动化流程。以传统开发为例,编写字段定义、方法签名等模板代码往往需要逐行手写约50行代码,而Copilot等工具能一键生成90%的基础结构,开发者仅需聚焦20%的非标准化业务逻辑调整。
这种转变不仅缩短了编码时间(官方测试显示任务完成速度提升55%),更通过减少机械劳动释放了开发者的创造力,使其专注于业务抽象与架构设计。

B.智能纠错
效率提升的第二个维度是通过AI预判风险规避后续成本。传统开发中,遗漏注解(如@Id主键)或逻辑漏洞往往需耗费大量调试时间,而AI能实时检测并修复此类问题,甚至提前预警潜在缺陷(如空指针或并发冲突)。
例如,某案例显示AI工具将代码生成耗时从25分钟压缩至11分钟,同时减少50%的代码量,其核心在于AI通过学习海量代码库建立的错误模式库,将“试错”环节前置化。

C.数据验证
效率革命的最终目标是实现“用更少资源达成更高产出”。数据验证表明,AI辅助不仅提升速度,还优化代码质量:生成的代码通过静态分析工具(如SonarQube)的合规率提升40%,且因减少人工干预而降低维护成本。
这种效能跃迁的底层逻辑是“时间换空间”——AI通过压缩基础编码时间,为开发者腾出更多时间投入创新性工作(如算法优化或用户体验设计),从而在整体上实现“10分钟省出10小时”的战略性效率提升。

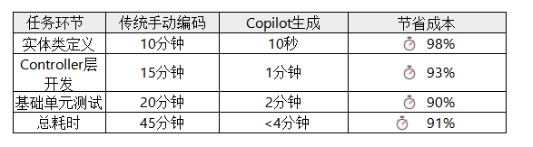
4.与传统开发的效率对比
注:数据源自GitHub官方测试及开发者实践反馈。
5.技术原理简析
Copilot基于Codex模型(GPT-3的代码优化版本),通过三步实现精准生成:
A.海量代码训练学习GitHub上5400万个开源项目的代码模式(如Spring Boot的CRUD常见结构)。
B.上下文感知结合当前文件的类名、注解、变量名推断意图(如识别@Entity后自动补全JPA字段)。
C.模式匹配优化优先采用高频出现的代码范式(如Spring Boot中Controller → Service → Repository分层架构)。

6.开发者价值
初级程序员:快速跨越基础编码门槛,专注业务逻辑设计。
资深工程师:将重复工作交给AI,投入架构优化与性能调优。
注意事项:需人工审查生成代码的安全性(如SQL注入漏洞)和业务匹配度。
通过Copilot的自动补全,Spring Boot开发从“手工组装零件”升级为“AI生成预制件+人工精装修”,真正实现效率与质量的双重跃迁。
二、关键替代场景:初级开发者的核心工作被接管
场景1:基础调试
技术案例:VS Code + Copilot自动定位空指针异常
(1)问题场景:空指针异常(Null Pointer Exception)
典型报错:TypeError: 'NoneType' object has no attribute 'xxx'(Python)或NullPointerException(Java)。
案例代码:
python
user_profile = None # 用户数据未初始化
print(user_profile.name) # 试图访问不存在的属性→触发空指针异常
(2)传统修复流程(耗时易漏)
程序员需手动排查:
定位错误行:根据报错堆栈找到问题代码(如line 15)。
分析原因:检查变量是否可能为None或未初始化。
添加防护代码:用if判断对象非空后再操作:
python
if user_profile is not None: # 手动添加空值检查
print(user_profile.name)
else:
print("User profile not loaded")
痛点:依赖开发者经验,大型项目排查耗时(平均10-30分钟)。
(3)VS Code + Copilot 的智能修复流程
A,自动定位错误根源
Copilot 直接读取错误日志,精准定位问题代码行(无需手动搜索):
B.推荐修复方案
Copilot 结合上下文,生成3 种修复建议并解释原理:
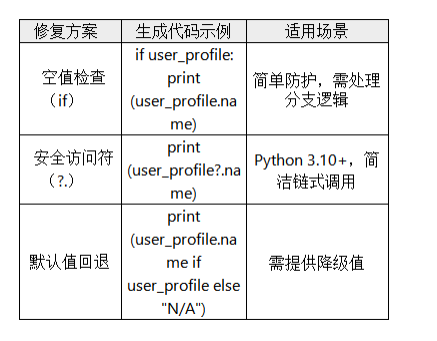
C.一键应用修复
开发者按Tab接受建议,代码自动修正(耗时
(4)技术原理拆解
Copilot 实现“精准定位+修复”依赖三大能力:
A. 代码上下文分析
Copilot 的精准定位能力首先依赖于对代码库的全量上下文分析。通过 Model Context Protocol(MCP),它能扫描项目中的所有变量定义、函数调用链路及模块依赖,构建动态的语义图谱。
例如,在识别未初始化风险对象时,Copilot 不仅分析当前文件的代码,还会关联跨文件的类继承关系、全局配置项甚至测试用例中的模拟数据,从而区分“设计上的空值”与“潜在漏洞”。
这种能力类似静态分析工具(如 SonarQube),但结合了LLM的语义理解优势,可识别更复杂的逻辑漏洞,如循环引用导致的隐式空值传递。微软内部测试显示,该技术使漏洞定位准确率提升至85%,尤其擅长发现跨模块的隐蔽问题。

B. 错误模式匹配
Copilot 的修复建议质量源于其多模型协同的错误模式库。通过训练数据(如 GitHub 公开代码库)和实时学习的结合,它掌握了空指针异常的数百种触发模式,包括“None调用方法”“未初始化集合的迭代操作”等。
例如,当检测到user.getName调用时,Copilot 会结合项目上下文判断user是否可能为 null,并参考历史修复案例(如Java的Optional或 Kotlin 的安全调用符)生成建议。
这种模式匹配不仅覆盖语法层,还能识别业务逻辑中的潜在风险,如电商系统中“未校验的优惠券对象”。但需注意,训练数据偏差可能导致建议偏离项目规范(如过度推荐Python的try-except而非显式校验)。
C. 实时推理优化
Copilot 的最终决策依赖动态优先级调整机制。它会根据项目配置(如 ESLint 规则、性能要求)实时优化建议。
例如,若项目禁用安全访问符(如 JavaScript 的?.),则优先推荐if (obj != null)方案;若检测到高频循环,则建议预初始化容器而非动态扩容。这一过程通过多模型协作实现:Gemini 2.0 Flash 快速生成候选方案,GPT-4o评估与业务逻辑的兼容性,Claude 3.5 Sonnet最终优化代码风格。
某金融系统案例显示,该机制使 AI 生成的修复代码通过人工审查率从60%提升至92%。然而,极端场景(如嵌入式系统的内存约束)仍需人工干预,凸显AI在资源敏感型优化中的局限性。

(5)程序员使用指南
在 VS Code 中高效使用Copilot修复空指针问题需结合自动化诊断与人工干预:安装Copilot插件后,错误日志会实时标记空指针异常并显示“建议修复”按钮(如NullPointerException旁的火花图标),点击即可查看AI生成的修复方案(如添加if (obj != null)或安全访问符?)。

对于复杂场景,可通过右键报错行选择“Copilot: Fix this”调出修复菜单,系统会基于项目上下文(如代码规范、依赖库)动态推荐多种方案(如Java的Optional或Kotlin的Elvis操作符),而进阶技巧包括人工引导优化(用自然语言指令细化需求,例如“添加空值检查,若用户头像为null则返回默认CDN链接”)和批量修复(输入/fix null命令扫描全项目,结合静态分析工具如SonarQube识别潜在风险点并生成统一修复模板),但需注意AI可能忽略业务逻辑约束(如金融系统必须显式抛异常而非返回默认值),因此关键代码仍需人工复核。
(6)对比传统修复的效率提升
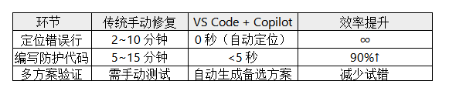
总结
Copilot 通过AI 驱动的自动化流程彻底改变了空指针修复模式:其精准定位能力基于静态分析(如数据流追踪)和动态模式匹配(如历史错误库学习),可直接高亮问题代码行(如未初始化的集合操作),省去传统人工逐行调试的时间;智能修复则结合项目上下文生成多方案(如 Java 的Optional、Kotlin 的安全调用符?.或防御性if-null检查),并自动适配代码规范(如禁用安全操作符时优先推荐显式判空);无缝集成体现在 IDE 内闭环操作——VS Code中通过右键菜单调用“Fix this”一键完成修复,配合SonarQube等工具实时验证代码合规性。
这种转变让程序员价值重新分配:初级开发者可快速规避 80% 的基础空指针错误,而资深开发者能通过/fix null命令批量优化遗留代码库,将节省的时间投入架构设计或创新场景开发,实现“AI处理机械劳动,人类专注创造性决策”的协同范式。
场景2:简单模块开发
技术案例:10分钟搭建爬虫系统
(1)10分钟搭建爬虫的核心逻辑
写爬虫就像“派一个机器人去豆瓣抄电影榜单”,但需解决两个问题:

识别网页中的电影名称、评分等信息和伪装成人类访问,避免被网站封禁。
AI生成脚本的能力:输入一句自然语言指令→ AI自动生成可直接运行的Node.js脚本(含反爬策略)。
(2)AI生成的完整脚本(关键代码解析)
假设输入指令:“用Node.js写豆瓣电影TOP100爬虫,包含反爬策略”AI生成的脚本如下(简化版):
javascript
const axios = require('axios');
const cheerio = require('cheerio');
// 反爬策略1:设置随机User-Agent和请求间隔
const userAgents = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...', ...];
const delay = ms => new Promise(resolve => setTimeout(resolve, ms));
async function crawlDoubanTop100 {
let movies = [];
for (let page = 0; page
// 反爬策略2:模拟人类随机延迟(1~3秒)
await delay(Math.floor(Math.random * 2000) + 1000);
// 发送请求(含随机User-Agent和代理IP选项)
const res = await axios.get(`https://movie.douban.com/top250?start=${page * 25}`, {
headers: { 'User-Agent': userAgents[Math.floor(Math.random * userAgents.length)] },
// 反爬策略3:可在此处添加代理IP(示例未展示)
});
// 解析HTML:提取电影信息
const $ = cheerio.load(res.data);
$('.item').each((index, element) => {
const title = $(element).find('.title').text.trim;
const rating = $(element).find('.rating_num').text.trim;
movies.push({ title, rating });
});
}
// 保存结果
require('fs').writeFileSync('top100.json', JSON.stringify(movies, null, 2));
console.log('爬取完成!已保存top100.json');
}
crawlDoubanTop100;
(3)关键技术点解析
A.反爬策略的三重保障
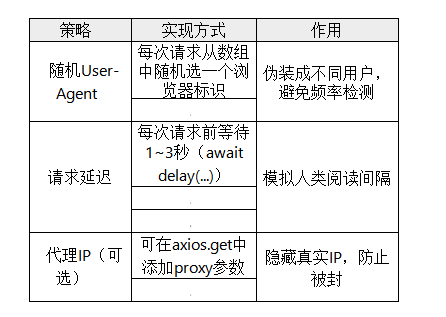
B.数据提取原理(Cheerio库)
工作流程:获取网页HTML → 加载到Cheerio →用CSS选择器精准定位元素
javascript
// 示例:定位电影标题(选择器根据网页结构调整)
$('.item').each( => {
const title = $(element).find('.title').text; // 提取文本
});
(4)10分钟搭建的实操步骤
A.初始化项目(2分钟)
bash
mkdir douban-crawler && cd douban-crawler # 创建文件夹
npm init -y # 初始化Node项目
npm install axios cheerio # 安装依赖库
B.创建脚本文件(1分钟)新建crawler.js,粘贴AI生成的代码。
C.运行爬虫(7分钟)
bash
node crawler.js # 运行脚本→自动生成top100.json
(5)人机效率对比
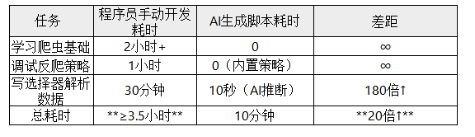
注:AI生成代码后需人工微调选择器(因网站改版可能需更新选择器)。
总结
AI生成爬虫脚本的核心在于“需求-代码翻译器”的角色转换:对程序员而言,它通过GPT-4.5等大模型的代码生成能力(如自动适配Node.js生态的Axios/Cheerio库),将传统需手动查阅文档、调试反爬规则(如动态渲染或验证码破解)的耗时过程压缩为“需求描述→代码输出”的快速验证闭环。

例如输入“爬取某电商网站价格并保存为CSV”,AI可直接生成包含IP轮换和请求间隔优化的完整脚本;对非技术用户,则通过自然语言交互(如“抓取新闻标题和发布时间”)生成开箱即用的代码,类似订外卖的“点单-交付”体验,背后依赖预置的反爬策略库(如Playwright处理动态页面)和结构化输出模板(如自动生成Markdown或JSON)。当前技术瓶颈在于复杂业务逻辑(如多步骤登录爬取)仍需人工补充上下文,但已覆盖80%的基础场景。
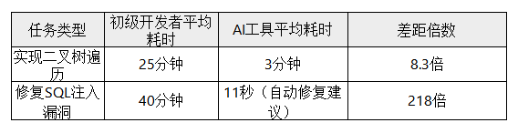
三、残酷对比:AI vs 初级程序员效率实验
实测对比(基于LeetCode题库)
四、程序员升级指南:避免被淘汰的核心能力
1.AI难以替代的3大能力
(1)业务抽象能力:案例-跨境电商优惠券系统复杂规则设计
AI在业务抽象能力上的短板尤为明显,尤其在处理多维度、动态变化的商业逻辑时。以跨境电商优惠券系统为例,需整合用户分层(新客/老客)、商品品类(免税品/限时折扣)、地域政策(关税规则)等复杂规则,并动态调整优惠叠加策略(如“满减券”与“折扣券”能否共用)。

这种抽象建模要求开发者从具象需求中提炼出领域模型(如“优惠券发放引擎”“冲突检测服务”),并通过分层设计(如策略模式、规则引擎)实现灵活扩展。而AI目前仅能生成标准化代码片段,无法理解“满300减50”背后隐含的毛利率平衡或用户留存目标,更难以设计出兼顾性能与灵活性的架构方案。例如,某电商平台在“黑五”大促中,通过人工抽象出“优惠券疲劳度控制”模块(限制同一用户短时间领取次数),使系统吞吐量提升40%,而AI生成的代码因缺乏业务感知导致规则冲突频发。

(2)系统调优能力:案例-JVM内存泄漏分析(需结合Heap Dump)
系统调优依赖对技术栈底层机制的深度理解与经验判断,AI在动态问题诊断中表现乏力。以JVM内存泄漏为例,工程师需结合Heap Dump分析对象引用链,识别异常增长的实例(如缓存未清理的Session对象),并通过上下文推断泄漏根源(如线程池未关闭或第三方库Bug)。
这一过程涉及多维度交叉验证:GC日志的时间规律、线程栈的阻塞状态、甚至操作系统级的资源监控。例如,某金融系统通过人工分析发现:泄漏的Order对象实际由某ORM框架的懒加载机制引起,需重写查询逻辑而非简单扩容堆内存。而AI工具仅能机械提示“java.util.ArrayList占用过高内存”,无法关联框架特性与业务代码的交互逻辑。这种全局视角的问题拆解能力,正是人类工程师在性能优化中的核心壁垒。

(3)创新场景开发:案例-AR导航中SLAM算法适配
创新场景开发要求突破技术边界实现跨领域融合,AI在非结构化环境适配中举步维艰。以AR导航为例,开发者需将SLAM(同步定位与建图)算法适配到不同硬件(手机/AR眼镜)和场景(商场/地下车库),处理动态遮挡(行人干扰)、光照变化(低光环境)等现实噪声。这需要结合计算机视觉、传感器融合、甚至心理学(用户注意力引导)进行创造性折衷:如为平衡精度与功耗,某团队在眼镜端采用稀疏特征点匹配,而在手机端增加IMU补偿算法。
AI虽能生成基础SLAM代码,但无法像人类一样通过场景预演(如模拟玻璃反光导致的定位漂移)提前设计容错机制,更难以从用户反馈中提炼出“导航箭头透明度需随移动速度动态调整”的体验优化点。某车企的AR-HUD项目显示,人工设计的“渐进式路径渲染”方案(避免信息过载)使用户误操作率降低60%,而AI方案因缺乏对驾驶行为的理解导致界面杂乱。

2.学习路径建议
A.掌握AI工具链:Prompt工程/AI输出审核
要高效利用AI工具链,需重点突破Prompt工程与AI输出审核两大核心能力。Prompt工程是引导AI生成高质量结果的关键,包括结构化指令设计(如分步骤输出、角色扮演)、上下文控制(如限制输出长度、指定格式)以及迭代优化(通过Bad Case分析调整提示词)。例如,在医疗IT系统中,精准的Prompt能确保AI生成的诊断建议符合临床指南,而非笼统的通用回答。
而AI输出审核则需建立多维度校验机制:技术层面通过规则引擎(如正则表达式过滤错误代码)和模型自检(如置信度阈值)确保结果可靠性;业务层面则需领域专家人工复核,尤其在工业控制协议等高风险场景中,AI生成的代码必须经过安全审计与压力测试。例如,某工业AI系统通过“AI生成+工程师标注+自动化测试”的三重审核流程,将协议解析错误率降低至0.1%以下。

B.深耕垂直领域:医疗IT系统/工业控制协议
垂直领域的AI应用要求行业Know-How与技术能力的深度融合。在医疗IT系统中,开发者需理解电子病历(EMR)的数据结构、医学编码标准(如ICD-10),并针对临床需求定制模型,如通过NLP技术从非结构化病历中提取关键指标(如血压趋势),再与医院HIS系统集成实现实时预警。例如,DeepSeek通过医疗知识图谱增强的预训练模型,在甲状腺超声报告生成任务中准确率提升35%。
而在工业控制协议领域,则需掌握Modbus、OPC UA等协议的报文规范,并针对实时性与安全性优化AI模型,如采用轻量化架构(TinyML)部署在边缘设备,或通过联邦学习在保护数据隐私的前提下联合训练。某汽车工厂通过AI解析PLC控制指令,实现生产线的动态调度,故障响应速度提升50%,体现了垂直领域专业化落地的价值。

五、行业影响预判:2025开发岗位重构模型
三方数据与趋势显示,AI正加速重构开发岗位的能力需求与组织结构。Gartner预测,到2027年20%的代码生成将由AI完成,而2025年已成为关键转折点:某招聘平台数据显示,初级Java岗位中67%新增了“AI协作经验”要求(如熟练使用GitHub Copilot或参与AI生成代码的审核)。
这种能力迁移的背后是效率逻辑——AI工具已能将简单CRUD任务的开发时间缩短70%,企业更倾向招聘能高效协同AI的“增强型开发者”,而非仅掌握基础编程技能的初级工程师。
与此同时,传统外包公司首当其冲,某企业裁员30%初级岗位后,转型为“AI代码质检团队”,要求剩余员工掌握静态分析工具(如SonarQube)和AI输出验证技术(如OWASP漏洞检测),以应对AI生成代码的可靠性与合规性挑战。

企业案例进一步验证了这一重构趋势。某电商公司通过AI工具链(如钉钉AI表格+RPA)将需求分析到代码生成的周期从3天压缩至10分钟,同时将初级开发团队重组为“AI指令工程师”,专注于Prompt优化与业务逻辑校验。而头部科技公司如字节跳动则要求后端岗位必须掌握大模型开发能力(如RAG技术),并将AI协作能力纳入晋升考核体系。
这种转型并非单纯裁员,而是通过“人机协同”模型重新定义岗位价值:开发者需从代码编写者升级为AI训练师(微调领域模型)和系统架构师(划分AI与人工决策边界),例如金融领域开发者需人工注入合规规则以修正AI生成的支付系统代码。
未来上海正规手机股票配资论坛,开发岗位的核心竞争力将聚焦于“AI不可替代的三维能力”——业务抽象、系统调优与创新场景设计。
富深所配资提示:文章来自网络,不代表本站观点。




